AI News
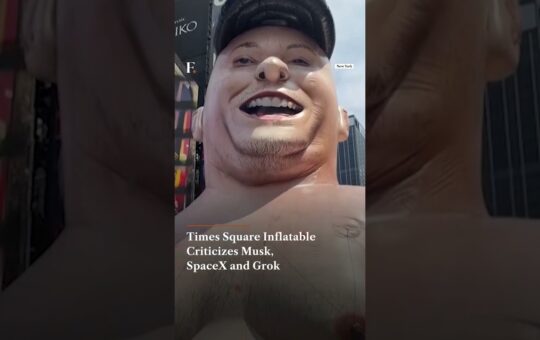
US public health agencies to test OpenAI and Anthropic AI models
Public health departments across the United States will test generative AI tools under a new programme involving the Coalition for...

Someone Fine-Tuned OpenBMB’s MiniCPM5-1B on Claude Fable 5 Traces to Ship a 657MB Local Thinking Model
A community developer, GnLOLot, has published a 1B model that runs fully on local hardware. The model is MiniCPM5-1B-Claude-Opus-Fable5-Thinking, with...

Data Centers Powering AI & Shaping Our Future #news
Check on YouTube

Intuit scrapped its own AI agent architecture twice in four months. At VB Transform 2026, its AI VP called that the fast path
Intuit was an early pioneer in the usage of agentic AI, but its path to success has hardly been a...

Kimi K3 vs DeepSeek V4 Pro vs GLM-5.2: Open Trillion-Scale MoE Models Compared on Benchmarks, License, and Serving Cost
Three Chinese labs now hold the top of the open-weight leaderboard. Moonshot AI’s Kimi K3, DeepSeek V4 Pro, and Zhipu...


Capital One releases VulnHunter, an open-source AI tool that finds software flaws before hackers do
Capital One on Thursday released VulnHunter, an open-source, agentic AI security tool that scans source code for exploitable vulnerabilities, maps...

Bunkerhill raises $55M to scale agentic AI across health systems
Bunkerhill Health has raised $55 million to scale its agentic AI platform, Carebricks.The closing of the company’s Series B round,...
AI News 11th June 2026
Check on YouTube

NVIDIA AI Releases Nemotron 3 Embed: An Open Embedding Collection Whose 8B Checkpoint Ranks #1 on RTEB
Embedding models decide which passages an agent ever sees. NVIDIA released Nemotron 3 Embed model to work on that layer....

China’s Moonshot AI releases Kimi K3, the largest open-source model ever, rivaling top U.S. systems
Moonshot AI, the Beijing-based artificial intelligence startup backed by Alibaba, on Thursday released Kimi K3 — a 2.8-trillion-parameter model that...
Apple’s New iPhone AI & Rising Prices | Off the Clock
Check on YouTube

Neko Health raises $700 million to expand AI body scans in the US
Neko Health has raised $700 million to expand its AI body scans in the United States, starting with a clinic...

Thinking Machines Lab Releases Inkling: A 975B-Parameter Open-Weights Multimodal MoE With 41B Active Parameters And Controllable Thinking Effort
Thinking Machines Lab just released Inkling, their first model trained from scratch, weights are open, fine-tunable on Tinker. The lab...
Apple’s WWDC 2026: Siri Reborn with Google Gemini? #ainews #shorts
Check on YouTube

Canva launches Code 2.0, offering AI website building to every user — including free accounts
Canva on Tuesday launched Canva Code 2.0, a major upgrade to its AI-powered coding tool that lets users build interactive...
AWS and Bluesight build AI for hospital 340B compliance
AWS (Amazon Web Services) has explained how Bluesight developed Prism, an AI layer that connects hospital pharmacy and compliance data...


Meet Blume: An Open-Source, Zero-Config Documentation Framework That Ships AI-Ready Docs From a Markdown Folder
Hayden Bleasel, an expert developer from OpenAI, released Blume, an open-source documentation framework. Blume shipped to npm as version 1.0.3...

ACRouter picks the smartest AI model per task, beating Opus-only setups by 2.6x on cost
Model routing is becoming a key component of the enterprise AI stack, dynamically sending prompts to the right AI model...